



Google unveils its 8th generation TPUs for AI Training and Inference


Google unveils its 8th-generation TPUs for AI training and inference
Google has just unveiled its 8th-generation of TPUs (Tensor Processing Units), announcing two separate TPU units for AI training and inference. These chips are Coogle’s 8t and 8i TPUs. These workload-specialised chips aim to deliver more performance per dollar, with more raw performance and more power efficiency at scale.
Both of these new TPUs will be available later this year and can be used as part of Google’s AI Hypercomputer platform.

Separate chips for AI Training and Inference
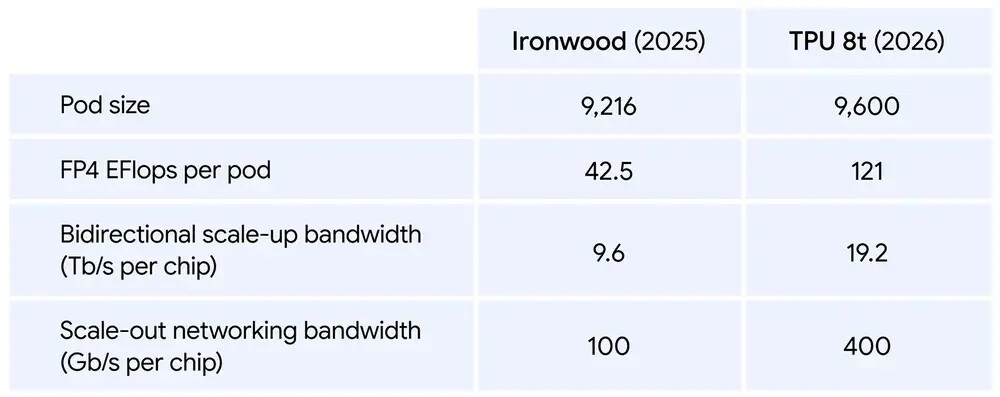
With TPU 8t, Google aimed to deliver more computational throughput and maximise interchip bandwidth. Google’s new 8t Superpods now scale to 9,600 chips with 2 petabytes of shared HBM memory and 3x the computational performance per pod as their last-generation Superpods.
With 10x faster storage access and their new TPUDirect feature, data can now be pulled directly into Google’s TPUs and delivered faster. This enables higher levels of hardware utilisation, boosting performance.
With their new 8t TPU, Google aims to reduce the AI model development cycle from months to weeks. This chip is targeted at training, where raw computational power is vital.
Big upgrades over Ironwood
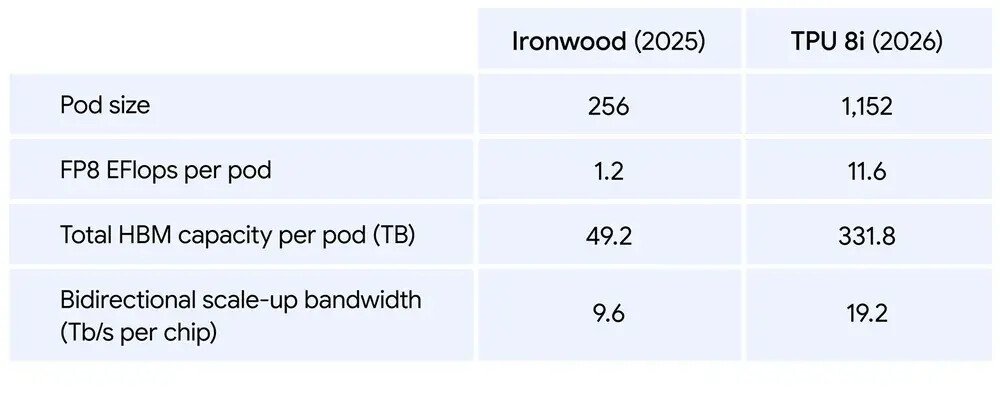
With Google’s 8i chip, Google pairs 288GB of HBM memory with 384MB of SRAM. This is 3x the SRAM of Google’s last-generation Ironwood chip. This allows Google’s new TPU to keep more data on chip, accelerating performance.
With 8i pods, Google has doubled the number of CPU hosts per server and started using its new Axion ARM CPUs. These changes deliver increased full system performance. New on-chip Collectives Acceleration Engines (CAEs) and Google have also minimised lag by reducing on-chip latencies by 5x.
Overall, these changes reportedly deliver 80% more performance per dollar to users. Google claims that businesses can nearly serve twice as many customers at the same cost as before.
With its 8th-generation TPU technology, Google has delivered boosted performance and increased value. That said, developing two separate chips moving forward would significantly increase development costs. It also means that their new chips are a little less versatile than their last-generation TPU, which was made for both Inference and Training. While purpose-built hardware has its advantages, more generalised hardware can be more readily used as workflows change. AI is an evolving market, so what’s optimal today could change tomorrow.
You can join the discussion on Google’s new 8th-generation TPUs on the OC3D Forums.
