



AMD Vega GPU architectural analysis


AMD Vega GPU architectural analysis
In both the compute world and the gaming world data sets have been becoming increasingly large, so much so that GPUs have simply not been able to keep up with the storage requirements of modern workloads.
GPU performance has been increasing at a much faster rate than memory (VRAM) capacity, with game installs becoming ever larger and texture requirements growing to insane levels. Today GPUs require a lot more VRAM than they did a few years ago, with 4GB becoming the norm for mid-range GPUs and 8GB starting to become commonplace.
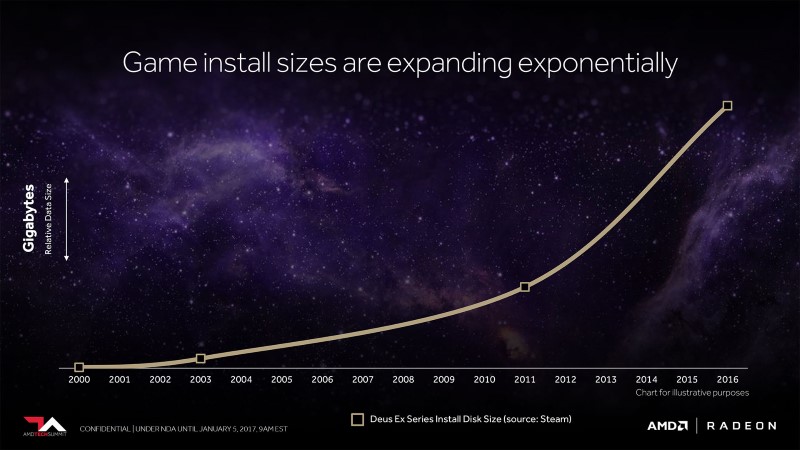

With resolutions reaching ever higher, compute loads getting more data intensive and game textures becoming increasingly large AMD thinks that a radical new memory solution is required for future GPUs, one that looks beyond traditional VRAM and into data sets that can reach up to 512TB in size.
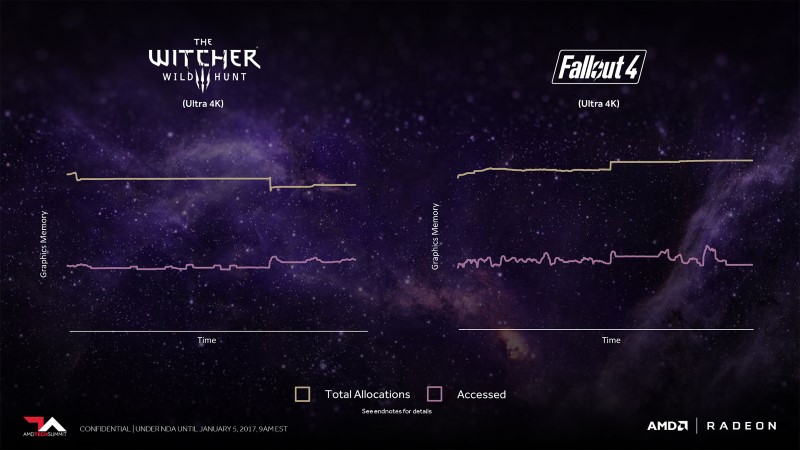
In modern gaming workloads, VRAM requirements can reach insane levels, though AMD has noticed an interesting trend, where games can require in excess of 8GB of VRAM but only require access to around 50% of the allocated data under most situations.
With only 50% of this data being used for a meaningful amount of time, it is reasonable to think that there can be a better way to manage video memory, perhaps one where not all of this data needs to be on your GPU’s VRAM.
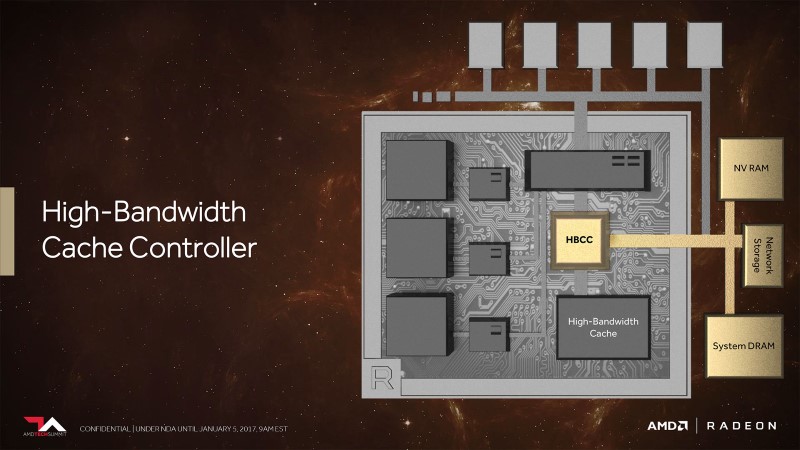
AMD’s solution to memory capacity problems is radical creating a new High Bandwidth Memory Controller (HBC) which allows the GPU to access memory outside the GPU alongside the GPUs traditional VRAM storage.
AMD is very vague about this new memory technology, but it effectively allows their Vega GPU to use data from your system memory, NVRAM (Non-Volatile flash storage) and even Network storage solutions. In effect this allows AMD’s Vega GPU to address up to 512TB of storage alongside the GPU’s HBM2 memory, allowing the GPU to use a seemingly limitless pool of storage if managed correctly.
AMD has showcased this type of memory solution before with their Radeon Pro SSG (Solid State GPU), which used an onboard M.2 NVMe SSD to have a frame buffer of 1TB. This solution was a clunky solution though it certainly leads to what we see now.
With Vega AMD is renaming what we would traditionally call a Frame Buffer (or VRM) into High Bandwidth Cache, which means that Vega’s HBM2 memory sits at the top of this while new GPU memory hierarchy and acts just as before, though now it completely changes what happens when the GPU “runs out of onboard memory”.
With normal GPUs when your run out of VRAM while gaming performance tanks, though now through clever memory management that may not be the case, with AMD’s new controller cleverly placing certain pieces of data into suitable memory for minimal performance impact. If this solution is implemented correctly user may not even notice if AMD Vega uses more than its traditional frame buffer, which is set to be a, not insubstantial, 16GB.

In the past, if you needed to use more memory than was in your GPUs frame buffer you would need to use your system memory, which adds a lot of latency and can slow performance down to a crawl, though with AMD’s new solution data can be allocated in a clever way to increase available memory without such a huge performance impact.
Previous solutions for this problem simply are not clever, adding a lot of needless latency and allocating data in a way which is not well suited to how often that data needs to be accessed and how quickly that data needs to be accessed.
With AMD’s Radeon Pro SSG, which accessed additional onboard memory through windows and not directly like their new Vega GPU, the company work with and scrub 5K videos in real-time at 90 frames per second, whereas current GPU offerings using traditional memory overflow methods was only able to achieve a mere 17FPS.
To say this least this memory allocation and control technology is exceptionally interesting and gives AMD the opportunity to become performance leaders in the High-Performance Compute market.
This technology will also have a huge impact on gaming performance, though only in scenarios when your GPU uses more than its onboard VRAM, which will play a significant role in the long-term usability of future AMD GPUs as textures get larger and games require more and more GPU memory.

On the next page, we will be discussing the changes to AMD’s Vega GPU Geometry and Compute capabilities.

Next Generation Geometry and Compute Engine Design
With Vega, AMD has not limited their architectural changes to just their memory, announcing several improvements to both their Geometry pipeline and their Compute units.
Vega now supports Primitive shaders, which is a new type of low-level shader that developers can use to specify all shading stages that they want, allowing them to run at a higher rate than shaders using the traditional DirectX shader pipeline model. In an ideal scenario, developers will work to perform these optimisations, though AMD can use their graphics driver to deliver pre-defined cases for games, where several DirectX shaders can be replaced by a single primitive shader for improved performance.
AMD has also improved their geometry pipeline to deliver much higher peak levels of geometry throughput, with AMD’s R9 Fury X offering 4 Geometry engines with peak throughputs of 4 polygons per clock, with Vega coming with 4 geometry engined that can handle up to 11 polygons per clock, a 2.6x increase.




With their next generation compute units AMD seeks to improve gaming performance with their Next Generation Compute Units (NCU), offering higher levels of mixed precision compute performance, greater 16-bit and 8-bit compute performance as well as higher clock speeds.
On the compute side, AMD’s NCU will also be capable of calculating 8-bit, 16-bit and 32-bit operations with perfect scaling, which is perfect for those that require higher levels of lower precision compute performance. This also opens up the option to do several of these varying precision levels of compute at the same time, with mixed precision compute capabilities.
With a new feature called “rapid packed math”, AMD can now clump 16-bit and 8-bit math together to increase the amount of compute tasks that AMD can do per clock. In theory, developers could optimise some of their code to run as 16-bit or 8-bit operations to increase GPU performance, which is something that developers are currently exploring in the PS4 Pro.
Lastly, AMD’s new compute unit designs will be better suited to running at higher clock speeds, which will allow AMD to deliver more performance by completing more clock cycles and well as increasing the performance that AMD can deliver per clock.




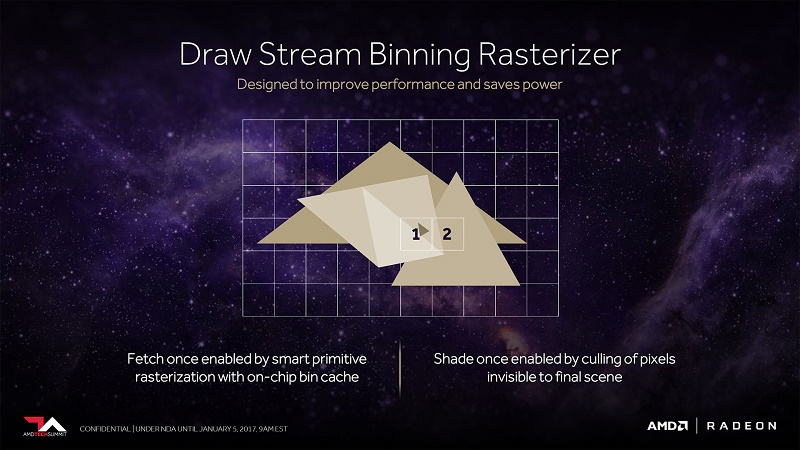
Draw Stream Binning Rasterizers
In simple terms, rasterisation is what turns 3D shapes in games into pixels, with AMD’s new Draw Stream Binning Rasterizer being a new option for AMD to use to cull pixels and improve performance in two ways.
First, this new method will help Vega to determine which pixels to shade and can reduce the work that the GPU needs to do. Pixels can only be one colour, but as you can see in the image below, multiple pieces of geometry can be present in that space. This new rasterizer will help the GPU to determine what data to use when shading, reducing memory access and power consumption.
AMD’s new DSBR approach is looking at Rasterization using a Tile-based method, which is done a lot on mobile products and has even been implemented on Nvidia GPU architectures since Maxwell. One other effect of this tile-based method is that is can effectively lower memory bandwidth requirements, which can give products a higher effective memory bandwidth when doing certain tasks.
The most important part of rasterization methods is that it eliminates pixels that are not visible in the rendered scene, which reduces the work that the GPU needs to do.
Nvidia has been using Tile-based rasterization methods ever since their Maxwell GPU architecture, though that was something that Nvidia kept under wraps until it was revealed in mid-2016.
Conclusion
All-in-all, AMD’s Vega architecture makes a lot of changes from their previous GPU designs, many of which will have a significant impact on AMD’s GPU performance.
AMD’s memory design alone can be seen as nothing but transformative, especially when considering the use of GPUs for compute rather than gaming. Now Vega can have access to seemingly limitless amounts of data, which has the potential to transform how people use GPUs, though in the gaming world performance benefits of this new memory controller design will be limited.
On the compute side, Vega will deliver a lot more GPU performance per Stream processor, with a design that will offer increased clock speeds as well as increased levels of work per clock cycle. These improvements will be seen from many angles, through the geometry pipeline through increased engine throughput and the use of Primitive shaders as well as in Vega’s NCUs which can offer significantly more GPU performance through the use of “Rapid packed math”.
A lot the changes to AMD’s GPU architecture will significantly improve AMD’s performance in both gaming and compute tasks, leaving the company in a great position moving forward.

You can join the discussion on AMD’s Vega architecture on the OC3D Forums.