



Nvidia plans to move to Multi-Chip GPU modules to scale past Moore’s Law

Nvidia releases paper presenting plans to create multi-package GPU complexes
Moore’s Law has been showing down for quite some time, with progress towards next generation processing nodes slowing down while hardware makers and consumers cry out for bigger and more powerful hardware.
Today companies are searching for ways to boost the performance of their products without the need for more advanced processing nodes or creating products that are almost unfeasible in scale. If hardware makers want to create bigger products moving forward they will need to think of a new way of scaling silicon to larger sizes, which is where technologies like AMD’s Infinity Fabric come into play.
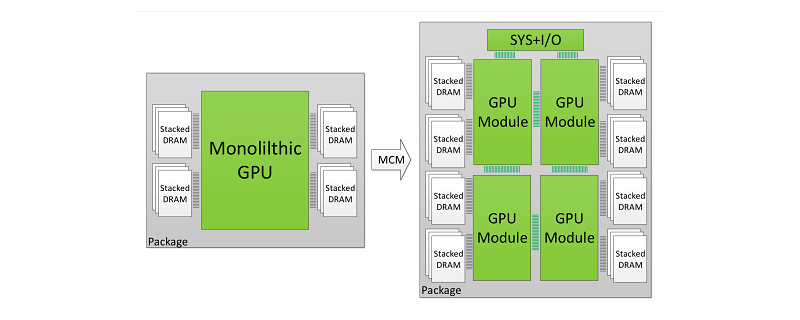
Nvidia also wants to scale their products beyond the limits of silicon, with the company now researching ways to create GPUs that are a multi-GPU complex that will be able to act as a single unit and produce levels of performance that are higher than a single, “monolithic” GPU structure.
In a new collaboration between Nvidia, Arizona State University, the University of Texas and the Barcelona Supercomputing Centre, research is being conducted to create a GPU that is an MCM (Multi-Chip-Module), which can work together with fast interconnects to function as a single, grand scale GPU design.
The advantages of an MCM are obvious, as it will allow Nvidia to scale beyond the limits of traditional silicon and create several GPU SKUs using the same building blocks. These individual components will be smaller and high-yield, which will also make the creation process of these new GPUs less wasteful and potentially more profitable.
Right now, Nvidia thinks that an MCM-GPU would be able to produce performance levels that are within 10% of a hypothetical superscale-GPU with the same number of CUDA cores and memory bandwidth, a GPU that would be unbuildable without MCM technology.
To address this need, in this paper we demonstrate that package-level integration of multiple GPU modules to build larger logical GPUs can enable continuous performance scaling beyond Moore’s law. Specifically, we propose partitioning GPUs into easily manufacturable basic GPU Modules (GPMs), and integrating them on package using high bandwidth and power efficient signaling technologies. We lay out the details and evaluate the feasibility of a basic Multi-Chip-Module GPU (MCM-GPU) design.We then propose three architectural optimizations that significantly improve GPM data locality and minimize the sensitivity on inter-GPM bandwidth. Our evaluation shows that the optimized MCM-GPU achieves 22.8% speedup and 5x inter-GPM bandwidth reduction when compared to the basic MCM-GPU architecture.
Most importantly, the optimized MCM-GPU design is 45.5% faster than the largest implementable monolithic GPU, and performs within 10% of a hypothetical (and unbuildable) monolithic GPU. Lastly we show that our optimized MCM-GPU is 26.8% faster than an equally equipped Multi-GPU system with the same total number of SMs and DRAM bandwidth.
Those of us who are well acquainted with the PC industry will be scratching their heads thinking “this sounds familiar”, as this research from Nvidia does seem reminiscent of AMD’s Infinity Fabric tech which allows AMD to create MCM-CPU complexes for their Threadripper and EPYC series CPUs.
AMD has also implemented Infinity Fabric into their latest Vega GPU architecture, with their next-generation Navi-GPU hardware promising enhanced “Scalability”, which suggests that AMD is ahead of Nvidia when it comes to creating an MCM-GPU.
You can join the discussion on Nvidia’s plans to create a multi-chip GPU complex on the OC3D Forums.
Nvidia releases paper presenting plans to create multi-package GPU complexes
Moore’s Law has been showing down for quite some time, with progress towards next generation processing nodes slowing down while hardware makers and consumers cry out for bigger and more powerful hardware.
Today companies are searching for ways to boost the performance of their products without the need for more advanced processing nodes or creating products that are almost unfeasible in scale. If hardware makers want to create bigger products moving forward they will need to think of a new way of scaling silicon to larger sizes, which is where technologies like AMD’s Infinity Fabric come into play.
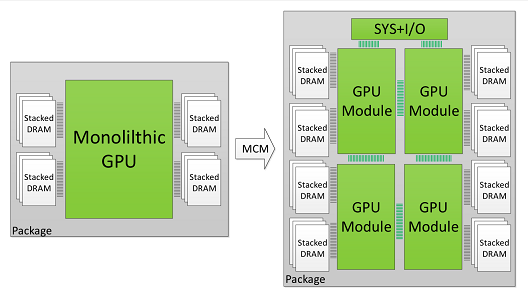
Nvidia also wants to scale their products beyond the limits of silicon, with the company now researching ways to create GPUs that are a multi-GPU complex that will be able to act as a single unit and produce levels of performance that are higher than a single, “monolithic” GPU structure.
In a new collaboration between Nvidia, Arizona State University, the University of Texas and the Barcelona Supercomputing Centre, research is being conducted to create a GPU that is an MCM (Multi-Chip-Module), which can work together with fast interconnects to function as a single, grand scale GPU design.
The advantages of an MCM are obvious, as it will allow Nvidia to scale beyond the limits of traditional silicon and create several GPU SKUs using the same building blocks. These individual components will be smaller and high-yield, which will also make the creation process of these new GPUs less wasteful and potentially more profitable.
Right now, Nvidia thinks that an MCM-GPU would be able to produce performance levels that are within 10% of a hypothetical superscale-GPU with the same number of CUDA cores and memory bandwidth, a GPU that would be unbuildable without MCM technology.
To address this need, in this paper we demonstrate that package-level integration of multiple GPU modules to build larger logical GPUs can enable continuous performance scaling beyond Moore’s law. Specifically, we propose partitioning GPUs into easily manufacturable basic GPU Modules (GPMs), and integrating them on package using high bandwidth and power efficient signaling technologies. We lay out the details and evaluate the feasibility of a basic Multi-Chip-Module GPU (MCM-GPU) design.We then propose three architectural optimizations that significantly improve GPM data locality and minimize the sensitivity on inter-GPM bandwidth. Our evaluation shows that the optimized MCM-GPU achieves 22.8% speedup and 5x inter-GPM bandwidth reduction when compared to the basic MCM-GPU architecture.
Most importantly, the optimized MCM-GPU design is 45.5% faster than the largest implementable monolithic GPU, and performs within 10% of a hypothetical (and unbuildable) monolithic GPU. Lastly we show that our optimized MCM-GPU is 26.8% faster than an equally equipped Multi-GPU system with the same total number of SMs and DRAM bandwidth.
Those of us who are well acquainted with the PC industry will be scratching their heads thinking “this sounds familiar”, as this research from Nvidia does seem reminiscent of AMD’s Infinity Fabric tech which allows AMD to create MCM-CPU complexes for their Threadripper and EPYC series CPUs.
AMD has also implemented Infinity Fabric into their latest Vega GPU architecture, with their next-generation Navi-GPU hardware promising enhanced “Scalability”, which suggests that AMD is ahead of Nvidia when it comes to creating an MCM-GPU.
You can join the discussion on Nvidia’s plans to create a multi-chip GPU complex on the OC3D Forums.