




Nvidia RTX 2080 and RTX 2080 Ti Review


Turing – A New Core Architecture
In the lead up the launch of Nvidia’s Turing graphics cards, perhaps the most overlooked aspect of the architecture is the radical redesign of Turing’s SM units, which are designed to deliver increased performance levels by offering users extra parallelism.
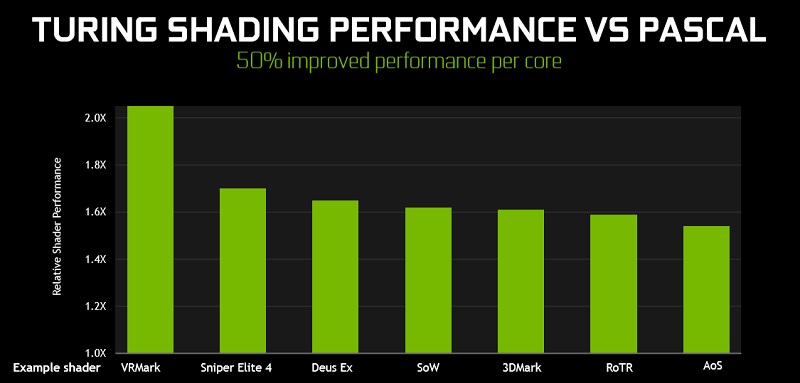
Nvidia estimates that their new Turing SMs can offer a 50% improvement in per core performance over Pascal, though the exact performance changes of Nvidia’s redesign will change on a game-by-game basis, depending on how much Nvidia’s concurrent Floating Point and Integer execution datapaths benefit specific workloads.
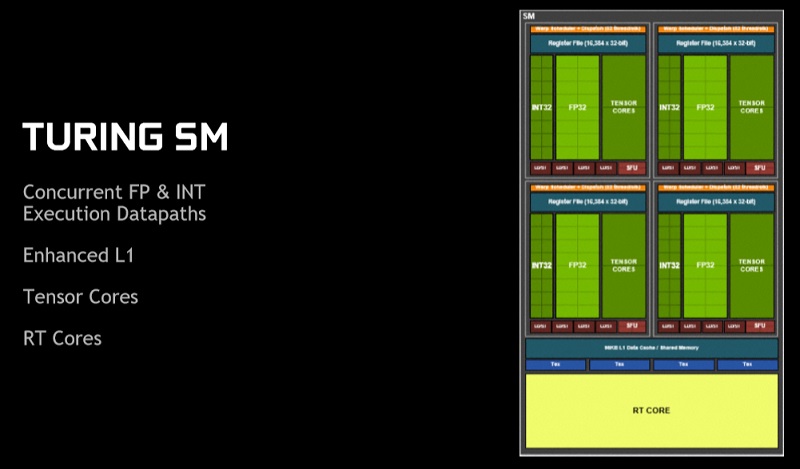
Nvidia’s new Turing SM units offer several new features, including integrated Tensor cores, an RT core and improvements to Nvidia’s cache hierarchy, which include increased cache capacities and lowered levels of L1 latency.
As you can see in the diagram below, Nvidia’s Turing SMs include Tensor cores and an RT core on the per-SM level, which means that Nvidia’s Turing and RT Cores are not mere side-blocks within the graphics cards that could be sacrificed in the name of die space savings. These features are implemented at the heart of Nvidia’s Turing architecture, making these features challenging to remove for lower-end SKUs, especially Nvidia’s Tensor cores.
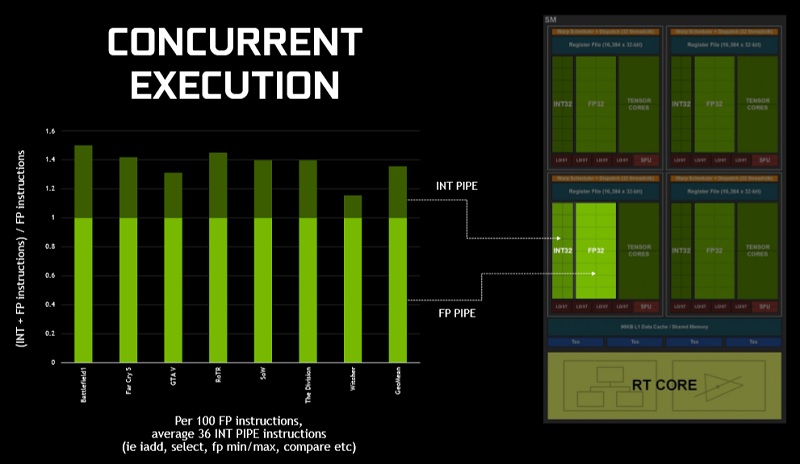
Perhaps the most impactful change within Nvidia’s Turing architecture, in today’s gaming workloads, is Nvidia’s use of what they call “concurrent execution”, which allows Integer and Floating Point calculations to be calculated at the same time.
This change adds an extra layer of parallelisation to Nvidia’s Turing architecture, allowing Nvidia to multi-task and complete workloads at a faster rate. In the slide below we can see performance gains of between 15% and 45%. The impact of this change will change on a game-by-game basis.
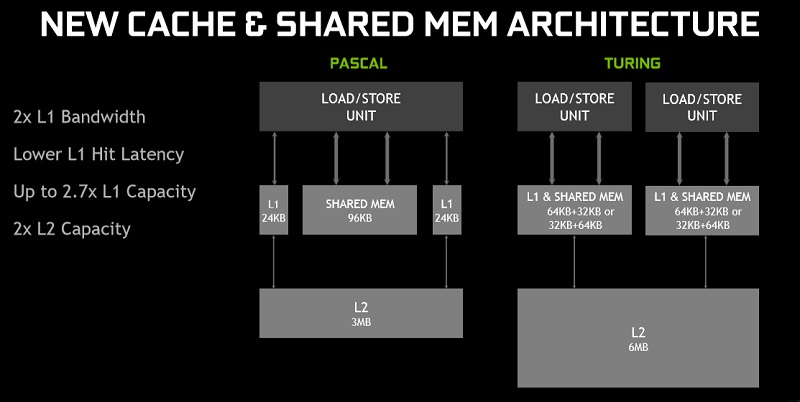
The final change is Nvidia’s use of larger cache’s and their integration of shared memory into their L1 cache, which allows the shared memory and L1 cache to be redistributed depending on the needs of specific workloads. Nvidia has also decreased the Hit latency of their L1 cache, making the cache more reactive, saving on potential idle time.
Turing also offers two times as much L2 cache as Pascal, likely thanks to the additional tasks that are now expected from Turing SMs, such as Ray Tracing and Tensor-based workloads.
Turing isn’t just Pascal with added support for Ray Tracing and Ai compute. Nvidia’s secret sauce also applied to standard gaming workloads, offering a boost in per core graphics performance over all of the company’s previous architectures.